留存分析
1. 留存分析概述
留存分析是一种用来分析用户参与情况/活跃程度的分析模型,考查进行初始行为后的用户中,有多少人会进行后续行为。这是衡量产品对用户价值高低的重要指标。
留存分析可以帮助回答以下问题:
一个新客户在未来的一段时间内是否完成了您期许用户完成的行为?如支付订单
某个社交产品改进了新注册用户的引导流程,期待改善用户注册后的参与程度,如何验证?
想判断某项产品改动是否奏效,如新增了一个邀请好友的功能,观察是否有人因新增功能而多使用产品几个月?
2. 留存分析界面功能简介
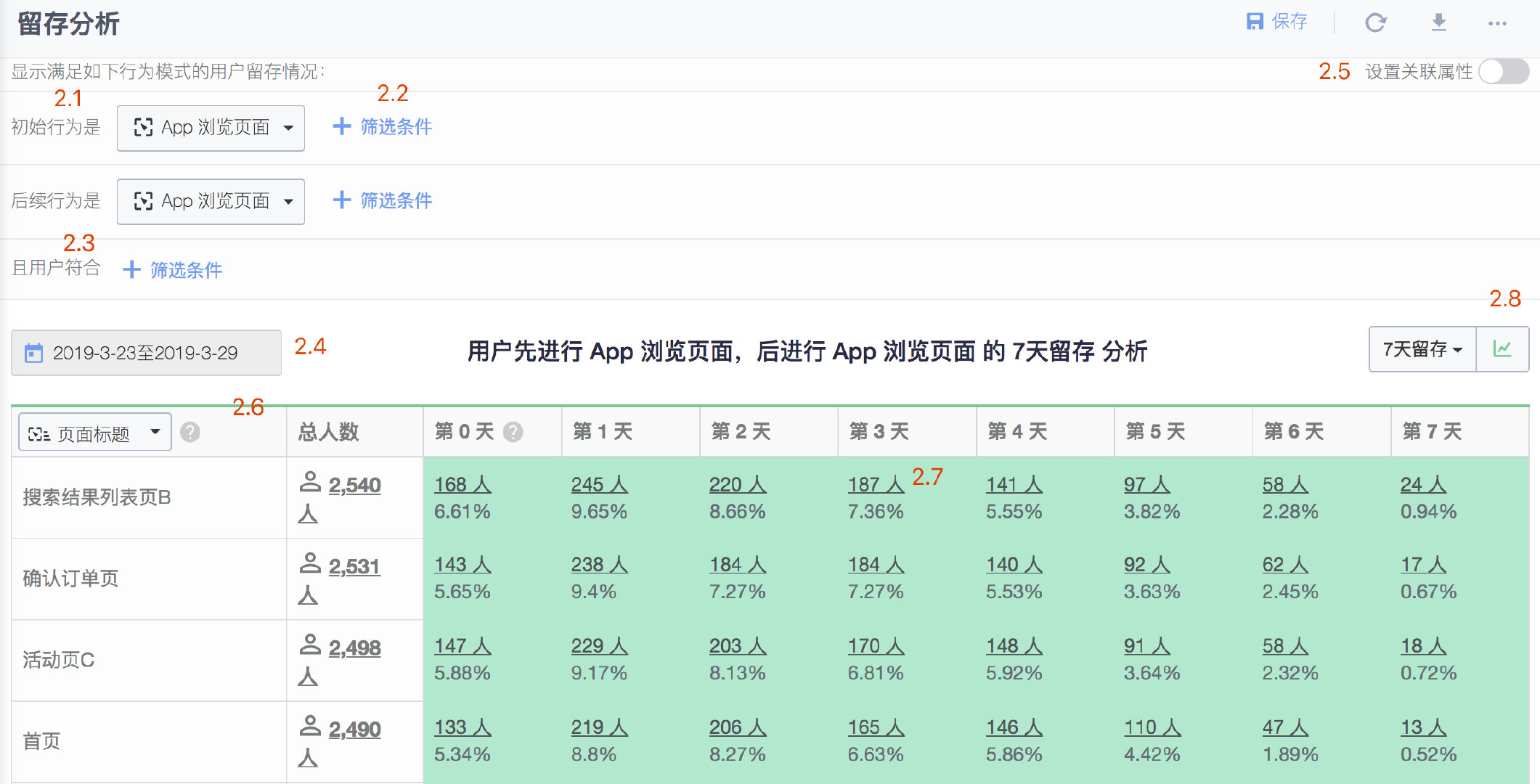
2.1 选择初始行为和后续行为
初始行为和后续行为的选择有两种策略:
初始行为选择用户只触发一次的事件,比如“注册”、“上传头像”、“激活设备”等,后续行为选择你期望用户重复触发的事件,比如“阅读文章”、“发帖”、“购买”等。这种留存用于对比分析不同阶段开始使用产品的新用户的参与情况,从而评估产品迭代或运营策略调整的得失。
初始行为和后续行为选择相同的,期待用户重复触发的事件。这种留存用于分析忠实用户的使用模式。
2.2 设置初始行为和后续行为筛选条件
针对事件的属性,可以根据具体需求筛选初始行为或后续行为的细分维度。比如,我们想分析北京地区的用户注册后,后续购买手机的留存情况,那么可以定义初始行为是“注册”,同时添加筛选条件“城市等于北京”,后续行为是“支付订单的商品细节”,同时添加筛选条件“商品类型等于手机”,即可满足分析需求。
2.3 设置用户筛选条件
针对用户属性,筛选合适的分析对象。比如,只查看女性用户的留存情况。
2.4 选择考查的时间段

这里选择的时间范围是初始行为事件发生的时间范围,如上图选择“7 天留存”,后续事件发生时间范围的截止日期会被延展到 2017 年 1 月 4 日( 2016 年 12 月 28 日向后延展 7 天)。
可以按照日、周、月查看不同时间体量下的留存/流失情况。1.6.5 版提供了查看流失用户的功能,在上图圈红处点击可以选择流失时间。

留存分析中流失用户的定义是连续多“天”没有发生后续事件才认为是流失用户,如上图“第2天”流失是指 103,582 人进行初始事件后持续 2 天没有进行后续事件。
2.5 设置关联属性
支持设置初始行为事件和后续行为事件的属性进行关联。不同事件关联的属性可以是相同属性,也可以是不同属性,但是要求属性的类型必须一致。 举例:某内容类网站想要知道各页面的七日留存,因此需要在初始行为事件App 浏览页面 和后续行为事件 App 浏览页面 中添加关联属性页面标题,此时就会按照该属性进行关联,以保证用户严格按照该模式配对。

2.6 留存表格

留存表格默认按照初始行为日期分组。每行的第一列代表了初始行为日期;第二列是在该日期触发了初始行为的总人数(独立用户数);后面各列,分别是在相应时间后触发后续行为的用户数,以及占初始行为人数的百分比。
除了可以按照初始行为日期进行分组查看外,还可以分别按照初始行为事件属性或后续行为事件属性进行分组查看。如选择初始行为事件属性按注册渠道进行分组,我们则可以看到不同注册渠道的后续留存情况。
需要注意的是,当开启设置关联属性后,仅支持按照初始事件的关联属性进行分组查看。如选择初始行为事件和后续行为事件的关联属性为页面标题,则可以看到不同页面的后续留存情况。
觉得有点复杂?没关系,鼠标悬浮到每个单元格上,会有文字提示告诉你这个单元格的具体含义。同时,单元格的背景颜色也能直观反映留存情况。

如果这里选择的属性是数字类型,可以自定义分组区间。如果没有设置,查询引擎会动态计算分组区间。此设置仅在当前查询生效,将查询保存为书签后在书签中也生效。
2.7 浏览用户详情
表格的单元格内的数字是可以点击的,点击可以浏览这些用户的详细信息,并且进一步浏览其中单个用户的详细行为序列。
2.8 留存变化趋势曲线
用另一种可视化方式,体现不同分组的留存情况对比。
3. 留存是如何计算的
留存分析中展示的数字代表独立用户数。表示在选定时间范围内进行了初始行为的用户,有多少人在随后的第 n 天/周/月进行了后续行为。
3.1 基本计算规则
假设定义的初始行为是 A 事件,后续行为是 B 事件,筛选时间段为 2015 年 1 月 1 日到 2015 年 1 月 8 日,注意这个时间范围是事件 A 发生的时间范围,事件 B 发生的时间范围是 2015 年 1 月 1日到 1 月 15 日(1 月 8 日加上 7 天)。
3.11 未设置关联属性
下表为某用户2015 年 1 月 1 日到 2015 年 1 月 8 日的真实行为序列和纳入计算的行为序列(保留用户当日首个初始行为事件或后续行为事件)。表格中,字母 A 和 B 为事件,数字 1,2,3 为该用户某个属性的属性值。
日期
真实行为序列
纳入计算的行为序列
01-01
A1,A2,A2
A1
01-02
B2,B1,B1
B2
01-03
A3,A1,A1
A3
01-04
A1,A3,A3
A1
01-05
A1,A3,A3
A1
01-06
B1,B2,B1
B1
01-07
A1,A2
A1
01-08
B2,B1,B3
B2
1.不加分组,如果指定初始行为日期为 2015 年 1 月 1 日,则该用户分别是第 1 天,第 5 天,第 7 天的留存用户。
2.按初始行为事件 A 的属性分组,如果用户完成事件 A 的属性值各不相同,该用户只会被归到 1 月 1 日 发生的首个 A 事件的属性值 1 中。去重后,该用户分别是属性值 1 的第 1 天,第 2 天,第 3 天,第 4 天,第 5 天,第 7 天的留存用户。
3.按初始行为事件 B 的属性分组,如果用户完成事件 B 的属性值各不相同,该用户只会被归到 1 月 2 日 发生的首个 B 事件的属性值 2 中。去重后,该用户分别是属性值 2 的第 1 天,第 2 天,第 3 天,第 4 天,第 5 天,第 7 天的留存用户。
4.按用户属性分组,比如按性别分组,若用户为女性,则该用户分别是属性值女性的第 1 天,第 2 天,第 3 天,第 4 天,第 5 天,第 7 天的留存用户。
3.12 设置关联属性
下表为某用户2015 年 1 月 1 日到 2015 年 1 月 8 日的真实行为序列和纳入计算的行为序列(同一天内初始行为事件或后续行为事件不同属性值各保留一个,且保留首个)。表格中,字母 A 和 B 为事件,数字 1,2,3 为该用户某个属性的属性值。
日期
真实行为序列
纳入计算的行为序列(属性值1)
纳入计算的行为序列(属性值 2)
01-01
A1,A2,A2
A1
A2
01-02
B2,B1,B1
B1
B2
01-03
A3,A1,A1
A1
01-04
A1,A3,A3
A1
01-05
A1,A3,A3
A1
01-06
B1,B2,B1
B1
B2
01-07
A1,A2
A1
A2
01-08
B2,B1,B3
B1
B2
按初始行为事件 A 的属性分组,如果按属性值 1 分组,则关联属性值为 1 的初始行为事件或后续行为事件才会纳入计算,该用户分别是属性值 1 的第 1 天,第 2 天,第 3 天,第 4 天,第 5 天,第 7 天的留存用户。如果按属性值 2 分组,则关联属性值为 2 的初始行为事件或后续行为事件才会纳入计算,该用户分别是属性值 2 的第 1 天,第 5 天,第 7 天的留存用户。同理,该用户分别是属性值 3 的第 3 天,第 4 天,第 5 天的留存用户。
3.2 筛选条件的含义
和其他分析功能一样,留存分析也提供了筛选功能。留存分析的筛选提供了两种不同的筛选类型。 1. 用户属性上的筛选:例如,我们添加的筛选条件是“性别”为“男”,则只有属性中“性别”为“男”的用户,才满足这个筛选条件,并且出现在筛选后的留存分析结果中; 2. 事件属性的筛选:和漏斗的触发限制条件含义相同,指定事件满足指定属性的过滤。
3.3 分组的含义
留存分析提供了两种不同的分组类型。我们以一个初始行为是 A,后续行为是 B,时间范围是 2015 年 1 月 1 日到 1 月 8 日的 7 天留存来进行详细说明:
用户属性上的分组:根据用户属性来进行更进一步的分组。例如我们添加的分组条件是“性别”,那么,就会分别对留存分析的结果按照“男”、“女”来进行分组;
事件属性的分组:例如,我们选择的分组设置是初始行为的属性“屏幕高度”,则这个分组表示,在 2015 年 1 月 1 日到 1 月 15 日这个时间范围内,按初始行为的“屏幕高度”这个属性的值来对他们进行分组;下面是几个具体的例子的描述:
某个用户在这个时间段内的行为序列是 A、B、C、A、B,第一次出现的 A 的“屏幕高度”值为“320”,第二次出现的 A 的“屏幕高度”值为“1080”,因为按照首次出现的 A 事件的“屏幕高度”来分组,所以这个用户会被划分到“320”这个分组的统计结果中;
某个用户在这个时间段内的行为序列是 A、A,这个用户在初始行为 A 事件后没有后续行为。第一次出现的 A 的“屏幕高度”值为“1080”,第二次出现的 A 的“屏幕高度”值为“320”,因为按照首次出现的 A 事件的“屏幕高度”来分组,所以这个用户会被划分到“1080”这个分组的统计结果中;
4. FAQ
4.1 为什么要做留存分析?直接看活跃用户百分比不够吗?
按初始行为时间分组的留存分析可以消除用户增长对用户参与数据带来的影响。如果产品目前处于快速增长阶段,很有可能新用户中的活跃用户数增长掩盖了老用户活跃度的变化。通过留存分析,你可以将用户按照注册时间分段查看,得出类似如下结论:“三月份改版前,该月注册的用户 7 天留存只有 15%;但是四月份改版后,该月注册的用户 7 天留存提高到了 20%。” 同理,按照非时间维度的留存分析具有类似价值,比如,可以查看新功能上线之后,对不同性别用户的留存是否带来不同效果。我们在分析用户的留存时,一定要根据实际的业务需求,找到有价值的后续行为,对用户的价值留存进行分析,才能对产品的优化和改进提供实质性指导建议。
Last updated
Was this helpful?